Plosives are usually introduced first because of the kind of constriction in the mouth by which they are produced (closing-compression-release). There are six of them: /p, b, t, d, k, g/.
- /p/ and /b/ are produced with the constriction at the lips (bilabial). In the case of / p /, the vocal folds (cords) produce no voicing, and is consequently known as a voiceless plosive; /b/ is voiced.
- /t/ and /d/ are produced with the constriction of the blade of the tongue against the ridge behind the upper teeth (alveolar); /t/ is voiceless.
- /k/ and /g/ are produced with the constriction of the back of the tongue against the back of the roof of the mouth, the soft palate (velar); /k/ is voiceless.
Four acoustic properties of plosives
- Duration of stop gap – silent period in the closure phase
i.e. the closure duration of /p, t, k/ are longer than /b, d, g/
- Voicing bar – a dark bar that is shown at the low frequencies and it’s usually below 200Hz
i.e. only for voiced plosives /b, d, g/ , which is a primary indicator of voicing in the spectrogram, and all kinds of voiced sounds, including vowels, show this voicing bar at such low frequencies
- Release burst – a strong vertical spike
i.e. In general, we observe a stronger spike for /p, t, k/ than for /b, d, g/
- Aspiration – a short frication noise before vowel formants begin and it is usually in 30ms
i.e. /p, t, k/ of stressed syllable in initial position e.g. /ph/ in pin. Aspiration is not the same as the release burst. The period of aspiration (which only some voiceless plosives have) is much longer than the very short release burst (which all released plosives have).
Figure 3.1 A spectrogram of "a pam, a tan, a kang"
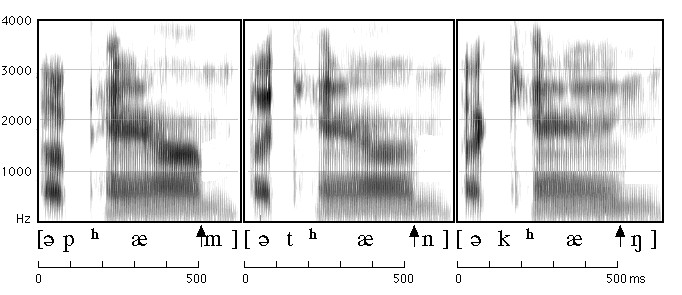
Figure 3.2
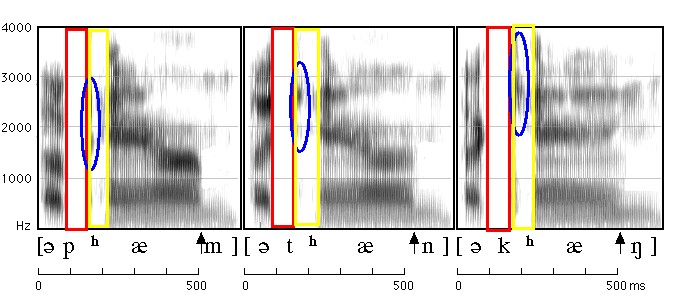
| Red | the stop gap in the medial phase of the /p//t//k/ (silence period) |
| Blue | the release burst of the /p//t//k/ |
| Yellow | the aspiration (delay of the onset of voicing for /æ/) |
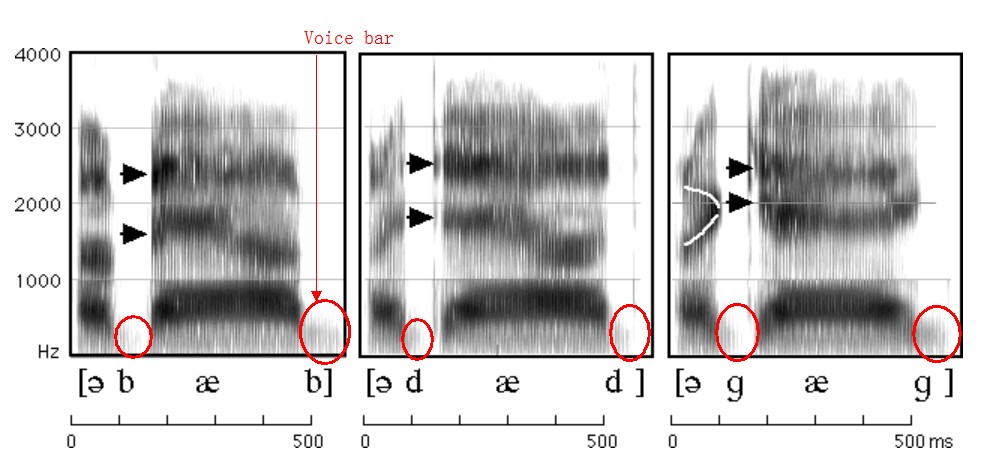
Voice bar refers to a dark bar that is shown at the low frequencies and it’s usually below 250Hz.Please see the voice bar of /b//d/and/g/ in intervocalic in Figure 3.3 for the voice bar of /b/,/d/and/ɡ/.
Figure 3.3 Spectrogram of the words "a bab, a dad, a gag" for the voicing bar
Retrieved from http://www.cog.jhu.edu/courses/325-f2004/ladefoged/course/chapter8/figure8.html
VOT (Voice onset time)
- VOT is a feature of the production of stop consonants. It is defined as the length of time that passes between the release of a stop consonant and the onset of voicing.
- It is the time interval including the release burst, a short frication noise after the spike, and the aspiration.
- VOT of Voiceless unaspirated stops, Voiceless aspirated stops, and Voiced unaspirated stops
- Voiceless unaspirated stops (e.g. [p]) have a voice onset time at or near zero, meaning that the voicing of a following sonorant (such as a vowel) begins at or near to when the stop is released.
- Voiceless aspirated stops (e.g. [ph]) have a voice onset time greater than unaspirated stops, called a positive VOT. The length of the VOT in such cases is a practical measure of aspiration: The longer the VOT, the stronger the aspiration.
- Voiced unaspirated stops (e.g. [b]) have a voice onset time noticeably less than zero, a negative VOT, meaning the vocal cords start vibrating before the stop is released. With a fully voiced stop, the VOT coincides with the onset of the stop; with a partially voiced stop, such as English [b, d, ɡ] in initial position, voicing begins sometime during the closure (occlusion) of the consonant.
Figure 3.4 shows graphical representation of the VOT of voiced unaspirated, voiceless unaspirated, and voiceless aspirated stops.
Figure 3.4 graphical representation of the VOT
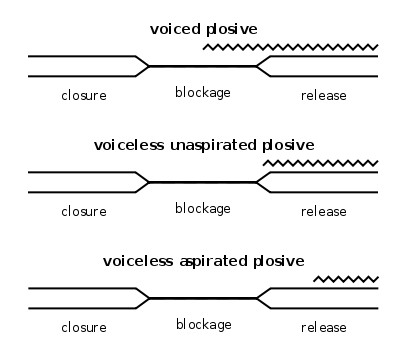
(Revised from http://en.wikipedia.org/wiki/Voice_onset_time)
Figure 3.5 Spectrogram of ‘aba’
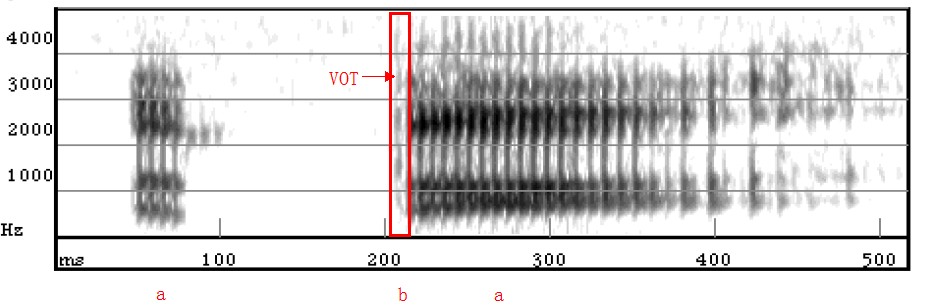
Note: [b] = voiced unaspirated. VOT is 0 to 20 milliseconds after stop release.
Figure 3.6 Spectrogram of ‘apa’
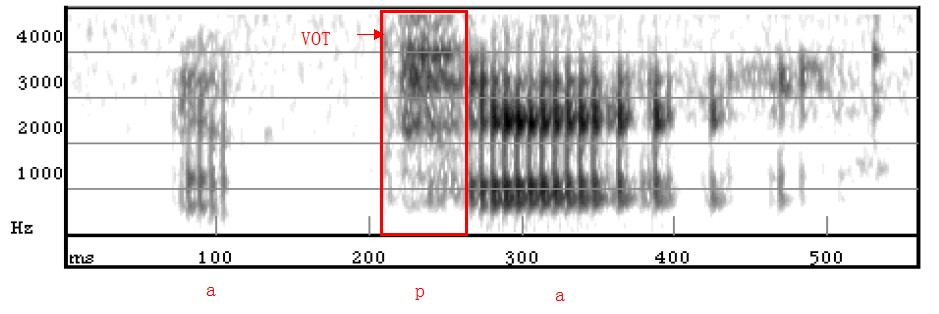
Note: [p] = voiceless aspirated.VOT is generally between 60 and 100 milliseconds.
Figure 3.7 Spectrogram of ‘aspa’
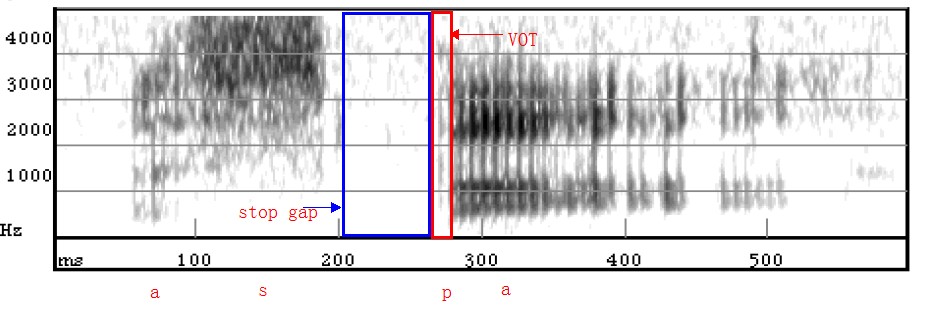
Note: After [s], [p] is voiceless unaspirated. VOT is from 0 to 20 milliseconds.
In Chinese pinyin system, we also have voiceless unaspirated [p] and voiceless aspirated [ph], but they are represented by letter "b" and "p" respectively. This is a little confusing, because "b" in English is a voiced stop, while in Chinese, "b" represents voiceless unaspirated [p], and there is no voiced consonant in Chinese. See Figure of Chinese pinyin syllable <pai> (clap) and <bai>(white).
Figure 3.8 Chinese pinyin syllable <pai> 派

Figure 3.9 Chinese pinyin syllable <bai>白

We will discuss how to measure VOT in Praat in detail in Chapter 4.
The following parts about the acoustic properties of consonants are revised from Stonham's phonetics lecture notes. Please find more details in the following link: http://stonham.dyndns.org/phonetics/handouts/eng_obs_hndt.pdf
- Labial Plosives: voiceless /p/ & voiced /b/
/p/ and b/ are produced with the constriction at the lips (bilabial). In the case of /p/, the vocal folds (cords) produce no voicing, and is consequently known as a voiceless plosive.
-
- The labial plosives, /p/ and /b/, may have several different realizations in English, which depends on the position where they occur. When voiceless /p/ is initial in a stressed syllable, as in "paper" or "popular", it is fairly strongly aspirated, symbolized [ph], while after /s/, the English voiceless bilabial plosive/p/ is not always aspirated, i.e. it shows no aspiration.
- High-intensity noise of /p/ and /b/ appears in the range of 3,000-5,000Hz.
- There is a third variety that appears at the end of the syllable, referred to as unreleased [p|].
- Alveolar Plosives:voiceless /t/& voiced /d/
/t/ and /d/ are produced with the constriction of the blade of the tongue against the ridge behind the upper teeth (alveolar). /t/ in initial position is aspirated as [th], like in "toy", but the /t/ following /s/ is unaspirated, thus /t/, like in store. There is a third variety that appears at the end of the syllable, referred to as unreleased [t|].
- Velar Plosives: voiceless /k/ & voiced /g/
/k/ and /g/ are produced with the constriction of the back of the tongue against the back of the roof of the mouth, the soft palate (velar); /g/is voiced while /k/ is voiceless. When /k/ is in word- or syllable-initial stressed position, the voiceless velar plosive is aspirated as [kh], and when preceded by [s], it has the same properties as the other plosives discussed so far.
What is "Locus Frequency"?
These formant transitions are perceptually important clues (or cues) to the manner (F1) and the place (F2 & F3) of the consonant. It is important to understand that the exact shape of the formant transitions will vary according to the neighboring vowel: they must start at the formant frequencies for the preceding vowel or they must end at the formant frequencies for the following vowel. However the frequency to which each transition is directed seems to be fairly consistent for a given consonant across different vowel contexts. These frequencies are called the consonant's locus frequencies (See Figure 3.10).
Figure 3.10 Schematic formant transition patterns for voiced stop-vowel syllables
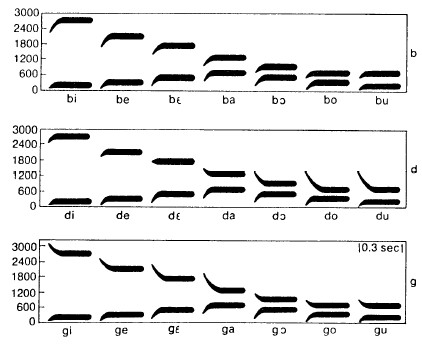
Voiced stops were better identified using formant transitions (see Figure 3.11).
Figure 3. 11 formant transitions of /b/, /d/and/g/
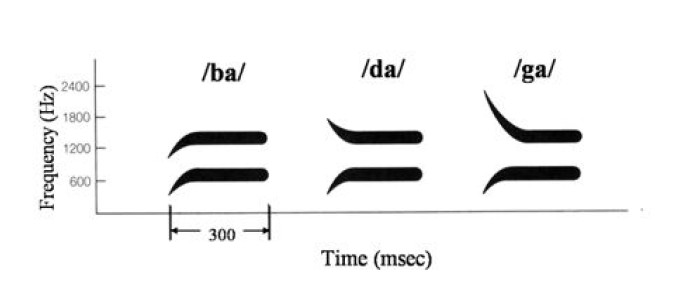
(Retrieved from http://www.lel.ed.ac.uk/~jkirby/hanoi/slides/lecture15-hanoi-4up.pdf)
Fricatives have a looser constriction in the mouth, which allows friction to be produced at the point of contact.
There are 9 fricatives: four pairs and /h/. Fricatives can be divided into sibilants versus non-sibilants. English sibilants include [s, ʃ, z, ʒ]. Sibilants involve a turbulent airstream that strikes an obstacle, such as the teeth.
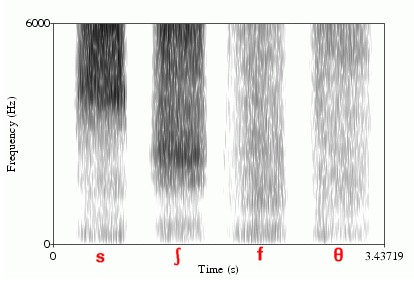
non-sibilants involve turbulence at the site of constriction sibilants tend to be louder than non-sibilants. Most of their acoustic energy occurs at higher frequencies, e.g. the bulk of the turbulence of both /s/ and /z/occurs above 3,500Hz, and reaching as high as 10,000 Hz, and /ʃ/ has most of its acoustic energy from around 2,000 Hz up to 10,000 Hz.
- Turbulence noise is stronger in sibilants /s, z, ʃ, ʒ/ than non-sibilant /f, v, θ, ð, h/.
- The intensity of labiodentals is lower than dental.
- The intensity of post-alveolar is lower than alveolar.
- Voiced fricatives /v, ð, z, ʒ/ have a longer noise time interval and higher frication noise.
- Voiceless fricatives /f, θ, s, ʃ/ have a weaker formants.
- For/h/, turbulent noise is very weak.
- For voiceless fricative, /s/ has a higher average frequency than/ʃ/does; and both are higher than /f/or /θ/.
Figure 3.12 Spectrogram of voiceless fricative /f/, /θ/, /s/, /ʃ/
- Voiced fricatives show aspects of both regular vocal fold vibrations and a randomly turbulent airstream. Different from their voiceless counterparts, the voiced fricatives have a substantial voicing bar occupying approximately the lower 400 Hz as shown in Figure 3.13.
Figure 3. 13 Spectrogram of voiced fricative /v/, /ð/, /z/, /ʒ/
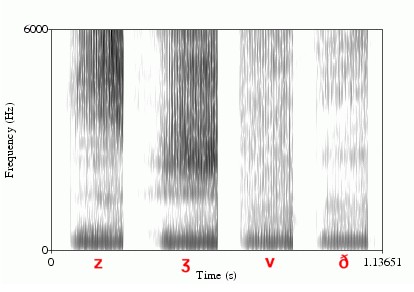
(Retrieved from http://home.cc.umanitoba.ca/~krussll/phonetics/acoustic/spectrogram-sounds.html)
A. Labio-dental Fricatives:voiceless /f/ & voiced /v/
There are two contrastive labio-dental fricatives in English, the voiceless /f/ and the voiced /v/.
The typical properties of /f/ include high frequency turbulence concentrated between 3,000-4,000Hz (Ladefoged, 2011: 56).
The voiced labiodental fricative /v/ also shows high frequency turbulence focused above 4,000 Hz, but it is not stronger than /f/.
There is no voicing bar with /f/, but there is a substantial voicing bar of /v/ occupying approximately the lower 400 Hz as shown in the following spectrogram (Figure 3.14).
Figure 3.14 Spectrogram of ‘afa’ and ‘ava’
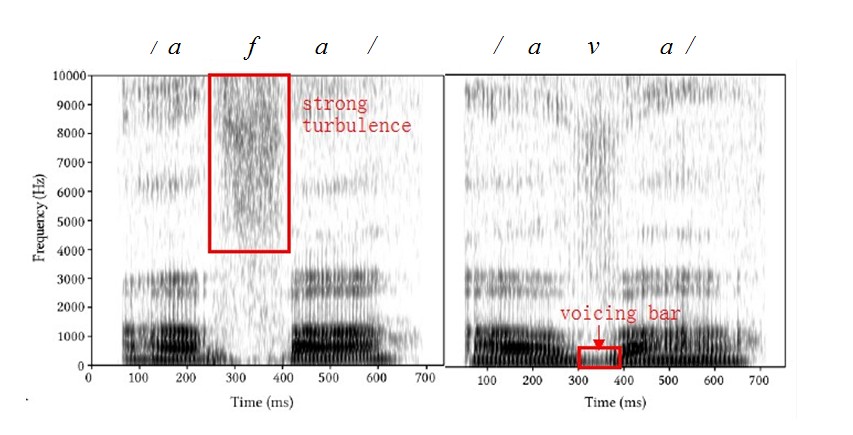
(Retrieved from http://stonham.dyndns.org/phonetics/handouts/eng_obs_hndt.pdf: p3)
B. Interdental Fricatives:voiceless/θ/& voiced /ð/
A second pair of fricatives has the constriction between the tip or blade of the tongue and the upper teeth (dental); they are both spelt <th>, The two words "thin" and "then" illustrate the two; in "thin", the <th> represents a voiceless fricative /θ/; on the other hand, the <th> in then is voiced and this has an IPA symbol /ð/.The turbulence for both begins at 2,500Hz.
Figure 3.15 Spectrogram of /aθa/ and /aða/
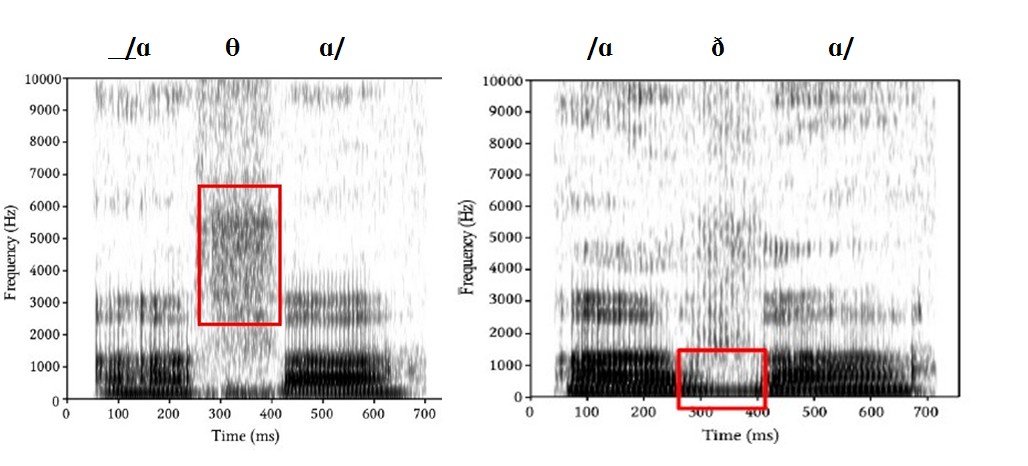
(Retrieved from http://stonham.dyndns.org/phonetics/lectures/eng_obs.pdf: p97&p98)
C. Alveolar Fricatives:voiceless/s/ & voiced /z/
The third pair of fricatives, /s/ and /z/ have the constriction between the blade of the tongue and the ridge behind the upper teeth (alveolar). With /z/ there is a voicing bar which cannot be found in /s/, and the bulk of the turbulence of both /s/ and /z/occurs above 3,500Hz.
Figure 3.16 Spectrogram of /asa/ and /aza/

(Retrieved from http://stonham.dyndns.org/phonetics/lectures/eng_obs.pdf: p102&p103)
D. Alveo-Palatal Fricatives:voiceless/ʃ/& voiced /ʒ/
The fourth pair has the constriction between the body of the tongue and the forward part of the roof of the mouth, immediately behind the teeth ridge (palato-alveolar, or pre-palatal).
The IPA symbol for the voiceless palato-alveolar fricative is like a letter <s> stretched high and low: /ʃ/; and is often represented by the letters <sh> in English – in fact, in the word English itself. The IPA symbol for the voiced palato-alveolar fricative looks like a handwritten <ʒ>.
The range of turbulence for both of these is from around 2,000 Hz up to 10,000 Hz , among which, /ʃ/ has most of its acoustic energy at around 4000Hz, extending up to around 8,000Hz.
Figure 3. 17 Spectrogram of /aʃa/ and /aʒa/
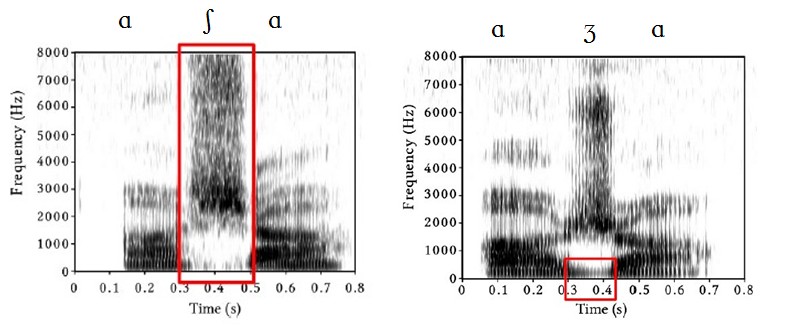
(Retrieved from http://stonham.dyndns.org/phonetics/lectures/eng_obs.pdf: p105 & p106)
E. Glottal Fricative /h/
The ninth fricative is /h/, which is voiceless at the beginning of a word but is voiced (breathy voice) in the middle of a word because the two voicing possibilities never contrast meanings of words in English. There is no voicing bar for /h/, and its turbulence appears to be strongest around 1,000 Hz.
Figure 3.18 Spectrogram of aha
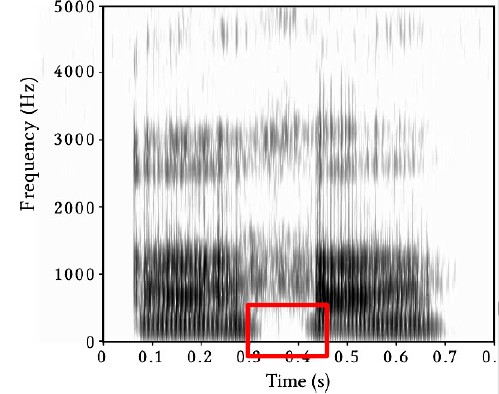
F. Sibilants[s, ʃ, z, ʒ]
- fricatives can be divided into sibilants versus non-sibilants; the English sibilants include [s, ʃ, z, ʒ].
- sibilants involve a turbulent airstream that strikes an obstacle, such as the teeth.
- non-sibilants involve turbulence at the site of constriction.
- sibilants tend to be louder than non-sibilants.
- most of their acoustic energy occurs at higher frequencies, e.g. the bulk of the turbulence of both /s/ and /z/occurs above 3,500Hz, and reaching as high as 10,000 Hz, and /ʃ/ has most of its acoustic energy from around 2,000 Hz up to 10,000 Hz.
The summary table of turbulence frequency and intensity of the fricatives
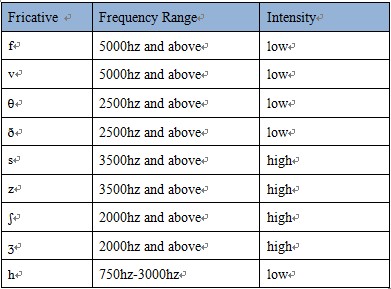
(The frequency value are excerpted from Ladefoged&Disner, 2012 and http://stonham.dyndns.org/phonetics/handouts/eng_obs_hndt.pdf)
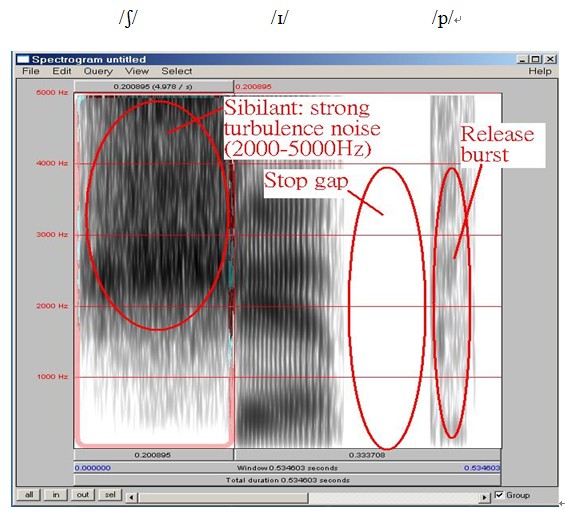
In the below spectrograms of "sip", "zip" and "ship", we can observe the fricative sibilants/s/, /z/,and /ʃ/ produce strong turbulence noise. Post-alveolar /ʃ/ has the strongest energy concentration 2,000-5,000Hz. Then, the energy concentration of voiced alveolar /z/ is stronger than voiceless alveolar /s/. We can see a stop gap and a vertical spike at the final position.
Figure 3.19 Spectrogram of sip
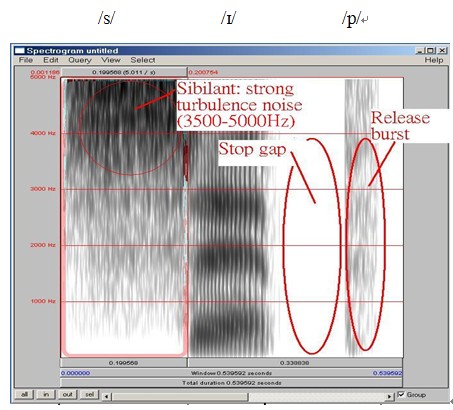
Figure 3.20 Spectrogram of zip
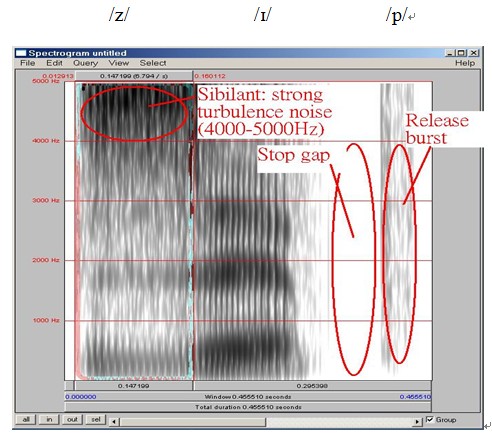
Figure 3.21 Spectrogram of ship
An affricate consonant is a close knit sequence of a plosive and a fricative produced by a single organ of speech (articulator). In English, there are just two. One is commonly spelt <ch> and occurs, for instance, in words like "chip" or "church"; its IPA symbol is /tʃ/ representing the sequence of plosive /t/and fricative /ʃ/ made by the body of the tongue in the palato-alveolar area. The symbol also indicates its voicelessness.
The other affricate occurs at the beginning of the word gem or judge and is commonly spelt with <g> or <j>, <dge>. Its IPA symbol is /dʒ/ ( a voiced combination of /d/ for the plosive element and /ʒ/ for the fricative element).
The bulk of the turbulence of both /tʃ/ and /dʒ/occurs above 2,000Hz.
Examples:
In the below spectrogram of jeep and cheep, the stop gap and fricative noise can be observed clearly. Moreover the fricative noise of voiceless /tʃ/ is longer than the voiced/dʒ/.
Figure 3. 22 Spectrogram of jeep

Figure 3. 23 Spectrogram of cheep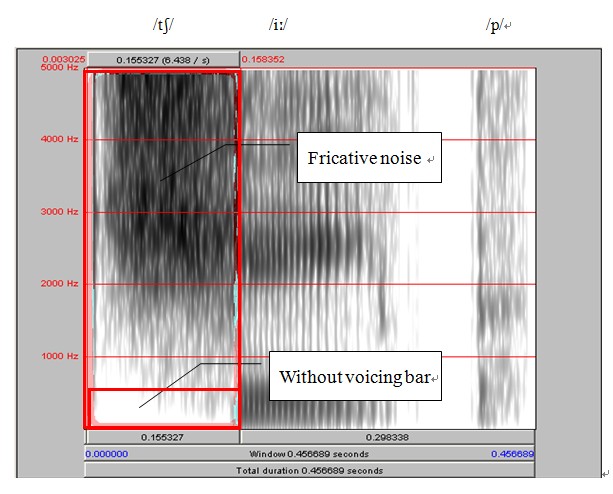
An approximant is a consonant in which the constriction made by an organ of speech (an articulator) is not great enough to produce any friction at all. The four approximants occur at the beginning of the words, like "lot", "rot", "yacht" and "what". Like vowels, approximants are:
- highly resonant
- produced with a relatively open vocal tract
- characterised by identifiable formant structures
- continuant sounds since there is no occlusion or momentary stoppage of the airstream
- non-turbulent due to lack of constriction
- oral sounds
They have faint formant structures that they all have a low F1 (below 1,000Hz) as they are voiced consonants (See Figure 3.24).
Figure 3. 24 A spectrogram of approximants in "led, red, wed, yell"
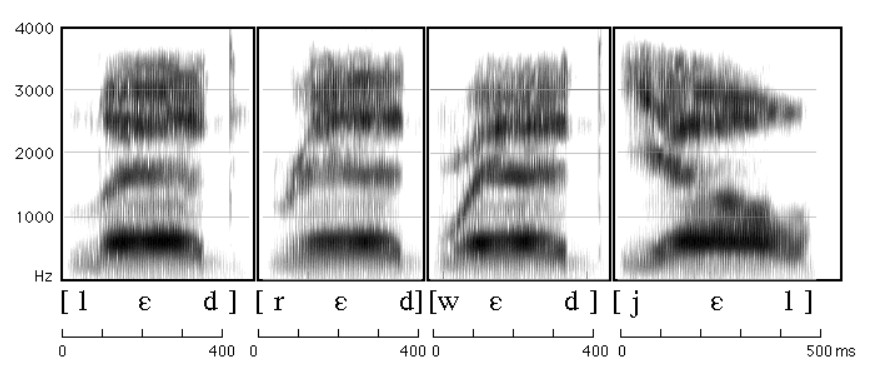
(Retrieved from Ladefoged (2006), A Course In Phonetics http://www.cog.jhu.edu/courses/325-f2004/ladefoged/course/chapter8/figure8.html)
A. Labial-velarapproximants/w/
For labial-velar approximants /w/, a large downward transition of F2 is characteristic due to the back tongue constriction. Lip rounding lowers the intensity of all formants particularly F3. So /w/ has F1 (250-450Hz), F2 (600 - 850Hz), and F3 (2,000 - 2,400Hz).
(The formant values were retrieved from Cox's website, http://clas.mq.edu.au/speech/acoustics/consonants/approxweb.html)
B. Palatalapproximants/j/
For palatal approximant /j/, the tongue is in the position for a front half close to close vowel (depending on the degree of openness of the following sound). Therefore it has a similar formant pattern to /i/. Lips are neutral to spread but rounded in anticipation of round vowels. It has a low F1 (200 - 300Hz) and a high F2 (1,850 - 2,100Hz) and F3 (2,620 - 3,050Hz).
(Cox, http://clas.mq.edu.au/speech/acoustics/consonants/approxweb.html)
/j/ and/w/ are traditionally called semi-vowels because, although they are formed like close vowels, they do not function as vowels. The approximant at the beginning of yacht has the IPA symbol is the letter < j > transcribed as / j / . Examples: you, youth, young, yet, yellow.
C. Alveolarapproximant /r/
The frequency of F1 appears to be related to lip rounding. i.e. low F1 = lip round.
/r/ is characterized by very low F3 due to retroflex articulation, which is usually below 2,000Hz, sometimes, falling to as low as 1,500Hz (Ladefoged, 2011:54). According to Cox, /r/ normally has F1 (300-350Hz), F2 (1,000-1,200Hz) and F3(1,600 -1,750Hz).
D. Alveolar lateral approximant /l/
English has one lateral phoneme: the lateral approximant /l/, which in many accents has two allophones. One, found before vowels as in" lady" or "fly", is called clear l, pronounced as the alveolar lateral approximant [l] with a "neutral" position of the body of the tongue. The other variant, so-called dark l found before consonants or word-finally, as in "bold" or "tell", is pronounced as the velarized alveolar lateral approximant [ɫ] with the tongue assuming a spoon-like shape with its back part raised. Since the two varieties never contrast meanings in English, together they constitute a single phoneme, and so only a single symbol is required.
Figure 3.25 A spectrogram of dark[ɫ] and clear [l]
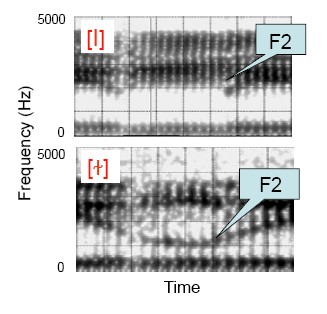
(From Recasens & Espinosa (2005), ‘Articulatory, positional and coarticulatory characteristics for clear /l/ and dark /ɫ/: evidence from two Catalan dialects’, JIPA 35(1), 1-25.)
For /l/, F1 is low and there is no continuous transition at vowel junctures, the difference between clear and dark /ɫ/ qualities are determined by the frequency of F2, as shown in the Spectrogram, F2 of dark/ɫ/ is lower than that of clear /l/.
Clear /l/
-
- F1 approx 200 - 400 Hz - F1 rises to all vowel targets except high front
- F2 approx 950-1,500Hz (lowest for back vowels)
- F3 approx 2,700-3,200
Dark /ɫ/
-
- F1 in the range 350-550Hz
- F2 in the range 650-850Hz
- F3 in the range 2,200- 2,700Hz
High intensity, particularly for syllabic /l/.
(Excerpted from Cox, retrieved from http://clas.mq.edu.au/speech/acoustics/consonants/approxweb.html)
Nasals have the same constriction as plosives except that air is allowed to pass through the nose but not through the mouth. There are three nasals in English: /m/ (bilabial), /n/ (alveolar) and /ŋ/ (velar); All nasals are voiced consonants.. The ‘ng’ sound represented by the velar nasal IPA symbol for the /ŋ/ is seen in words such as bank, anger and bang. They are formed by an oral closure accompanied by an open nasal passage. Both airflow and acoustic vibration pass through the open velar port into the nasopharyx and nasal cavities. And nasals reveal the abrupt loss of overall energy. The nose is less efficient than the mouth in radiating the energy to the outside.
Nasals involve a heavy voicing bar demonstrating their voicing, and in addition, they have formants like vowels, although they are somewhat lighter. The nasal is also less prominent on the waveform, although still more than an obstruent. The individual place of articulation of the nasal is indicated by the adjacent vowel formants, and these properties appear in either onset or coda position. There is a clear discontinuity between the formants of the nasal and those of adjacent sounds. Like stops, the crucial information is contained in the formant transitions. From the following spectrogram, we can find the patterns of formant transitions preceding 3 nasals.
The formants of all these three nasals are not as dark as they are in vowels. The frequency of F1 is very low (200-450 Hz) and the F3 is more visible (2500Hz). F2 is generally not visible (Please see Figure 3.26).
- [m] shows a fairly level F1 with a downward sloping F2
- [n] shows a downward slope for both F1 and F2
- [ŋ] shows an upward direction for F2 and a downward direction for F3
Figure 3.26 The spectrogram of three nasals
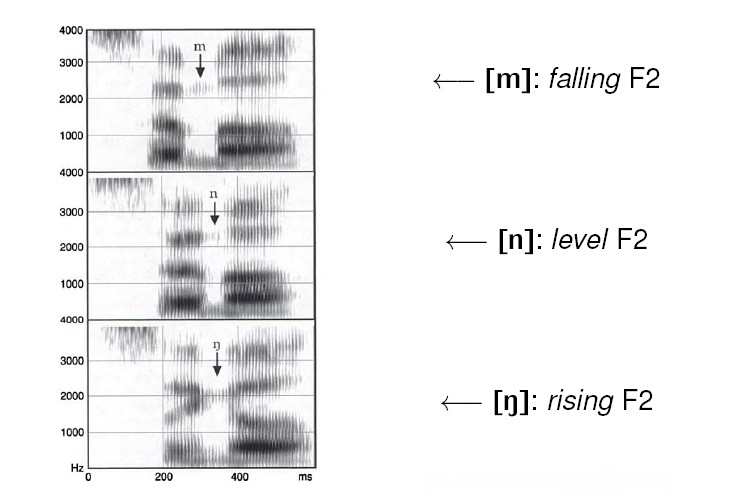
(Pictures retrieved from Ladefoged (2003), Phonetic Data Analysis: An Introduction to Fieldwork and Instrumental Techniques, Malden, MA & Oxford: Blackwell Pub http://www.lel.ed.ac.uk/~jkirby/hanoi/slides/lecture15-hanoi-4up.pdf)
When /m/, /n/ and /ŋ/ are found before another consonant, the voiced or voiceless nature of the final consonant has an effect on the length of both the vowel and the nasal consonant, the sounds /m/, /n/ and /ŋ/ are longer when followed by the gentle voiced consonant than when followed by the strong voiceless consonant. From the spectrogram below, we can easily find that the /m/ in symbol /'simbl/ is longer than the /m/in simple /'simpl/.
Figure 3.27 The spectrogram of simple

Figure 3.28 The spectrogram of symbol
Hits: 135284